In meinen ersten beiden Semestern als Gastdozent an der Lancaster University Leipzig beantwortete ich Dutzende von Fragen zu Prüfungsvorschriften, Abgabeterminen und akademischen Richtlinien. Darf ein internationaler Student zwei Wochen vor Semesterende nach Hause fliegen? Kann ich meinen Report später abgeben, ich war… krank? (Gesagt hat niemand „Party“, aber ich bin ja nicht blöd.) Und was passiert eigentlich, wenn mein Report länger ist als erlaubt? Jedes Mal musste ich entweder Kollegen fragen oder mich durch das Manual of Academic Regulations and Procedures (MARP) der Lancaster University kämpfen, ein Dokument, das alle Antworten enthält, aber nicht unbedingt will, dass man sie findet.
Ich bin Product Owner bei bitaggregat, wo wir bitSeekr entwickeln, ein Zero-Day Intrusion Detection System. Im vergangenen Jahr haben wir LLMs in bitSeekr integriert, um Berichte, Erklärungen und Filter für erkannte Attacken zu generieren. LLMs halfen uns, ein echtes Problem zu lösen. Mit ihnen erreichten wir deutlich verbesserte Fehlerquoten.
Im August kam dann eine E-Mail von der Uni: „Es zeichnet sich ab, dass wir Unterstützung in einigen Modulen brauchen.“ Da ich schon einmal Gastdozent war, lag es wohl nahe, mich zu fragen. Im Oktober stand ich vor der Aufgabe, einen projektbasierten Software-Engineering-Kurs zu konzipieren. Die Vorgabe: Studenten beibringen, wie man eine vernetzte Anwendung über 10 Wochen mit Scrum entwickelt. Die Wahl des Projekts lag bei mir.
Angesichts meiner Arbeit mit LLMs bei bitSeekr war die Entscheidung naheliegend: Die Studenten sollten ein RAG-System (Retrieval-Augmented Generation) von Grund auf bauen. Kein LangChain. Kein LlamaIndex. Nur die Grundlagen, Chunking, Embeddings, Context-Engineering und LLMs. Und das MARP-Problem lieferte den perfekten Use Case. Ein Chatbot, der Fragen zu akademischen Vorschriften beantwortet, gebaut mit Microservices-Architektur, Event-Driven Design und einer selbst erstellten RAG-Pipeline. Meine 14 Studenten, verteilt auf vier Teams, hatten begrenzte Erfahrung mit verteilten Systemen. Die meisten hatten noch nie einen Microservice gebaut, nur wenige verstanden ereignisgesteuerte Architekturen. Und wir hatten 10 Wochen Zeit.
Kernvoraussetzungen
Die technischen Anforderungen waren nicht verhandelbar:
- Microservices-Architektur: Keine Monolithen. Jeder Service sollte eine einzige, klar definierte Verantwortung haben.
- Event-Driven Architektur: Services kommunizieren über Events, nicht über direkte HTTP-Aufrufe. Mindestens fünf verschiedene Event-Typen im finalen System.
- Selbst erstellte RAG-Pipeline: Chunking, Embeddings, Retrieval und Generierung von Grund auf implementieren. Keine RAG-Frameworks: nicht LangChain, nicht LlamaIndex, nicht Haystack, nicht OpenWebUI.
- LLM-Integration: OpenRouter mit erlaubten kostenlosen Modellen. Der Chatbot muss Zitate liefern, ein Zitat pro Antwort für Assessment 1, zwei für Assessment 2. (Ehrlich gesagt wollte ich damit vor allem die Komplexität zwischen den Assessments steigern. Im Nachhinein war der Unterschied trivial, ob ich ein Ergebnis aus der VectorDB hole oder zwei, ändert architektonisch wenig.)
- Deployment: Alles läuft über Docker Compose mit Health Checks und Logging.
Das Framework-Verbot führte zu interessanten Reaktionen. Die Studenten merkten schnell, dass ich nur bei RAG Einschränkungen gemacht hatte und versuchten prompt, fertige Chat-Frameworks für den Rest zu nutzen. In den Gesprächen erklärte ich, dass es nicht darum geht, möglichst schnell irgendeine Lösung hinzustellen. Sie sollten verstehen, wie RAG funktioniert, wie Softwareentwicklung im Team abläuft, nicht nur wie man es konfiguriert. Das wurde größtenteils gut aufgenommen.
Projektstruktur
Der Kurs lief 10 Wochen. Ich wollte die 14 Studenten in vier Teams aufteilen: zwei Vierer-Teams und zwei Dreier-Teams.
Die Realität war komplizierter. Am ersten Termin tauchten nur sieben Studenten auf. Ich ließ sie zwei Teams bilden. Das führte später zu Konflikten, ein Team wollte noch einen Freund dazuholen, der nicht da gewesen war. Die restlichen Studenten forderte ich per E-Mail auf, selbst Teams zu bilden und mir bis zur zweiten Vorlesung Bescheid zu geben. Es kamen Rückfragen wie: „Können wir auch ein 5-Personen-Team bilden?“ Nein, denn dann hätte ein anderes Team nur zwei Leute, zu wenig für dieses Projekt. Irgendwann stand die Aufteilung.
Jedes Team folgte Scrum mit Sprint-Planung, regelmäßigen Standups, Reviews und Retrospektiven, dokumentiert über GitHub Issues und Projects.
Das Projekt hatte zwei Bewertungsmeilensteine:
- Assessment 1 (Anfang November): Funktionsfähige RAG-Pipeline mit mindestens einem Zitat pro Antwort, mindestens drei Event-Typen, grundlegende Microservices-Architektur.
- Assessment 2 (Mitte Dezember): Vollständiges MVP mit mindestens zwei Zitaten pro Antwort, mindestens fünf Event-Typen und zwei zusätzliche Features, ein grundlegendes und ein fortgeschrittenes.
Die Feature-Beschreibungen hielt ich bewusst vage. „Benutzerauthentifizierung“ oder „Hybrid Search“, ohne Details. Das spiegelte echte Produktarbeit wider, wo Anforderungen selten vollständig spezifiziert ankommen.
Natürlich legten die Studenten erstmal einfach los, ohne nachzufragen. Dass die Features zu vage waren, merkten sie erst, als sie tatsächlich mit der Umsetzung anfangen wollten. Da diese Features aber ohnehin für die zweite Kurshälfte geplant waren, passte das Timing: Wir hatten inzwischen Sprint Planning und andere Scrum-Prozesse besprochen, und plötzlich ergab das Konzept der Refinement-Gespräche mehr Sinn.
Was Studenten bauten
Bei der ersten Bewertung Anfang November zeigten sich deutliche Unterschiede zwischen den Teams. Ein Team hatte einen funktionsfähigen MARP-Chatbot: Er beantwortete Fragen korrekt, lieferte Zitate und gab zu, wenn er die Antwort nicht wusste. Ein zweites Team war nah dran, auch wenn noch nicht alles rund lief.
Die beiden anderen Teams hatten mehr zu kämpfen. Bei einem war zum Zeitpunkt der Bewertung kaum etwas lauffähig – es fehlte noch am Verständnis der grundlegenden Konzepte, und ohne das Verständnis haperte auch die Umsetzung. Das verbesserte sich im späteren Kursverlauf, aber zu diesem Zeitpunkt war der Rückstand sichtbar.
Bei den Embedding-Modellen habe ich die Studenten etwas in Richtung all-MiniLM-L6-v2 gelenkt. Die Ergebnisse waren gut genug, also blieben die meisten dabei. Bei den LLMs war es anders: Da haben die Teams viel experimentiert – Llama 3, Gemma, DeepSeek und andere. OpenRouter machte das einfach, weil der Wechsel zwischen Modellen nur eine Zeile Code ist.
Trotz des kleinen MARP-Corpus demonstrierten die funktionierenden Systeme bereits Skalierbarkeit, Parallelismus und Service-Isolation. Aber wie funktioniert diese Architektur eigentlich im Detail?
Technische Architektur
Der MARP-Chatbot erforderte drei Architektur-Muster, die zusammenarbeiteten: eine RAG-Pipeline für Wissens-Retrieval, eine ereignisgesteuerte Architektur für Service-Koordination und ein Microservices-Design für Modularität.
RAG-Pipeline-Grundlagen
Das RAG-System hat fünf Phasen: Discovery, Chunking, Embedding, Retrieval und Generierung. Die Studenten implementierten jede davon selbst.
Discovery findet und lädt die MARP-PDFs. Die Studenten mussten Metadaten wie Dokumenttitel, Abschnittsnummern und Veröffentlichungsdaten extrahieren, diese werden später für die Zitate entscheidend.
Chunking teilt Dokumente in semantisch sinnvolle Abschnitte. Hier merkten die Studenten schnell, dass nicht jede Strategie mit jedem Embedding-Modell funktioniert. all-MiniLM-L6-v2 hat ein Kontextfenster von nur 256 Token. Absatz-basiertes Chunking scheiterte damit, weil das MARP auch längere Absätze enthält. Die Teams wichen auf satzbasierte Chunks mit Überlappung aus oder nutzten ein Sliding Window mit fester Größe.
Embedding konvertiert Text-Chunks in Vektordarstellungen. Die meisten Teams verwendeten all-MiniLM-L6-v2, das 384-dimensionale Vektoren erzeugt. Wichtig: Das Embedding-Modell muss konsistent sein, dasselbe Modell für Dokumente und für Benutzerabfragen.
Retrieval findet die relevantesten Chunks für eine Abfrage. Die Studenten implementierten Cosinus-Ähnlichkeitssuche über Vektor-Datenbanken wie Qdrant oder ChromaDB. Der Retrieval-Service gibt die Top-k-Chunks zurück, typischerweise k=3 bis k=5.
Generierung schickt die abgerufenen Chunks zusammen mit der Benutzerfrage an ein LLM. Die Prompt-Vorlage strukturiert den Kontext: Sie definiert die Rolle des Assistenten, liefert die Textpassagen mit Quellenangaben und gibt Anweisungen für Zitate. Ein typisches Template sah ungefähr so aus:
You are a helpful assistant answering questions about Lancaster University's
academic regulations (MARP).
Context:
{chunk_1_text}
Source: {chunk_1_metadata}
{chunk_2_text}
Source: {chunk_2_metadata}
Question: {user_question}
Provide an answer using only the information in the context above.
Include at least two citations using the source metadata.
If the context doesn't contain the answer, say "I don't know."Das LLM generiert eine Antwort und soll Zitate aus den Metadaten extrahieren. Die Studenten mussten die Ausgabe validieren: Verweisen die Zitate tatsächlich auf die bereitgestellten Quellen, oder hat das Modell halluziniert? Ein Team versuchte das sogar mit automatischen End-to-End-Tests zu lösen.
Ereignisgesteuerte Architektur
Services rufen sich nicht direkt auf. Stattdessen veröffentlichen und konsumieren sie Events über einen Message-Broker.
Warum Events statt direkter Aufrufe? Vor allem wegen der Entkopplung. Der Ingestion-Service muss nicht wissen, dass ein Chunking-Service existiert. Er veröffentlicht DocumentExtracted und macht weiter. Wenn später ein Monitoring-Service dazukommt, der die Dokumentverarbeitung trackt, sind keine Code-Änderungen nötig.
Dazu kommt Skalierbarkeit: Wenn Chunking zum Engpass wird, deployt man einfach mehr Instanzen. Der Message-Broker verteilt die Arbeit automatisch. Und Resilienz: Wenn der Embedding-Service abstürzt, stauen sich Events in der Queue. Nach dem Neustart arbeitet er die Queue ab. Kein Datenverlust.
Für Studenten, die EDA noch nie gesehen hatten, war das schwer zu greifen. Sie wollten, dass Services sich einfach gegenseitig aufrufen. Ich erklärte es immer wieder am Beispiel der Pipeline: Der Discovery-Service findet MARP-Dokumente und schickt für jedes gefundene Dokument sofort ein Event. Während er noch nach weiteren Dokumenten sucht, kann der nächste Service, Download oder Extract, schon am ersten Dokument arbeiten. So entsteht eine parallel arbeitende Pipeline. Und falls ein Service langsamer ist als die anderen, deployt man einfach zwei oder drei davon per Docker Compose.
Die meisten Teams verwendeten RabbitMQ. Das lag auch an meinen Slides, wo ich RabbitMQ, Kafka und Redis verglichen hatte. Für unseren Use Case, moderate Nachrichtenmengen, einfaches Setup, kam RabbitMQ am besten weg.
Microservices-Design
Jeder Service hat eine einzige Verantwortung. Die Datenpipeline (Ingestion bis Indexierung) fließt durch Events. Die Abfrage-Pipeline (API bis LLM) verwendet synchrone HTTP-Calls. Diese Trennung ermöglicht unabhängige Skalierung und Deployment.
Die Studenten taten sich anfangs schwer damit, Dinge zu trennen. Sie wollten Services bauen, die mehrere Aufgaben übernehmen. Warum kann der Extraction-Service nicht auch Chunking machen? Er hat doch schon den Text. Ich musste immer wieder erklären, warum Trennung sinnvoll ist, gerade in Verbindung mit EDA. Wenn die Report-Formatierung sich ändert, will ich nicht die Detection-Logik anfassen müssen. Services mit einzelnen Verantwortungen sind einfacher zu verstehen, zu testen und auszutauschen.
Jeder Service läuft in seinem eigenen Docker-Container. Docker Compose orchestriert Deployment, Netzwerk und Health Checks.
LLM-Integration und Zitate
OpenRouter bietet eine einheitliche API für mehrere LLM-Provider. Die Studenten experimentierten mit kostenlosen Modellen: Llama 3, Gemma, DeepSeek und andere. Der Wechsel zwischen Modellen ist trivial, eine Zeile Code.
Die Zitat-Anforderung erzwang sorgfältiges Prompt-Engineering. Die Studenten mussten Kontext-Chunks mit klaren Metadaten strukturieren und das LLM anweisen, explizit auf Quellen zu verweisen.
Vom Produkt zum Klassenzimmer
Software-Engineering zu unterrichten unterscheidet sich vom Bauen von Software. In der Produktarbeit ist Ambiguität ein Feature. Anforderungen entstehen. Kunden denken, sie wissen, was sie wollen, bis du ihnen die erste Iteration zeigst. Deshalb funktioniert Scrum: für einen Sprint bauen, mit Stakeholdern reviewen, Kurs anpassen, wiederholen. So vermeidest du, das Falsche zu bauen.
Ich habe diese Philosophie bewusst in den Unterricht übernommen.
Beabsichtigte Ambiguität
Bei bitaggregat sind Kundenanforderungen selten präzise. Jemand sagt „Ich möchte besseres Filtern für erkannte Attacken.“ Was sie meinen: „Ich möchte keine Fehlalarme in meinem E-Mail-Report.“ Die echte Anforderung entsteht durch Gespräch und Iteration.
Das habe ich im MARP-Projekt repliziert. Feature-Beschreibungen waren bewusst vage. „Benutzerauthentifizierung“ könnte einfaches Username/Passwort bedeuten oder OAuth mit rollenbasierter Zugriffskontrolle. Die Studenten mussten nachfragen und den Scope aushandeln.
In Woche sechs fragte ein Team, ob die Chat-Historie Gesprächs-Threads oder eine flache Liste unterstützen sollte. Meine Antwort: „Was hältst du für sinnvoller für den Benutzer?“ Sie entschieden sich für die flache Liste, vermutlich beeinflusst davon, was einfacher zu implementieren war. Aber das ist okay und passt zum Scrum-Vorgehen: Iterate fast, validate often. Wenn mir als Kunde die flache Liste nicht gefällt, fällt mir das im nächsten Review auf.
Dass die Anforderungen vage waren, zwang die Studenten, mehr mit mir zu interagieren. Mein Eindruck nach zwei Kursen als Dozent: Viele Studenten wollen Wissen passiv aufnehmen, wenn überhaupt. Zu Diskussionen und Fragen aufzufordern holt sie aus ihrer Komfortzone. Das war für manche unbequem, aber bis zum Ende des Kurses verstanden die meisten, warum Anforderungen nicht immer vollständig sein können.
Die Erfahrungslücke
Die größere Herausforderung war technische Erfahrung. Die meisten Studenten hatten Anwendungen gebaut, aber keine verteilten Systeme. Sie verstanden Klassen und Funktionen, aber nicht Service-Grenzen.
Das schwierigste Konzept war die Service-Verantwortung. Studenten wollten anfangs, dass ein Service mehrere Aufgaben übernimmt. Warum kann der Extraction-Service nicht auch Chunking machen? Er hat doch schon den Text. Ich erklärte es immer wieder: Wenn sich die Chunking-Strategie ändert, willst du nicht den Extraction-Code anfassen müssen. Services mit einzelnen Verantwortungen sind einfacher zu verstehen, zu testen und auszutauschen.
Lehrbelastung
Der Kurs behandelte RAG, Microservices, Scrum, GitHub-Workflows, Docker, Event-Driven Architecture, Vektor-Datenbanken und LLM-APIs. Für Studenten mit begrenzter Erfahrung war die Lernkurve steil.
Ich verbrachte viel Zeit mit Grundlagen. Was ist ein Message-Broker? Wie entwirft man ein Event-Schema? Warum müssen Embeddings konsistent sein? Das sind keine trivialen Fragen für Anfänger.
Im Präsenzteil arbeiteten die Studenten innerhalb ihrer Teams gut zusammen. Ich hätte mir gewünscht, dass sie auch über Team-Grenzen hinweg mehr kooperiert hätten, das passierte weniger. Gen-AI-Tools waren erlaubt, und die meisten nutzten sie sinnvoll, auch wenn bei einigen noch Luft nach oben war.
Über den Code hinaus
Akademische Projekte lehren wissenschaftliche und technische Fähigkeiten. Professionelle Arbeit verlangt Kommunikation, Zusammenarbeit und Iteration unter Unsicherheit. Das alles in 10 Wochen zu vermitteln ist ambitioniert. Aber zu sehen, wie Studenten diese Lücke schlossen, war der lohnendste Teil.
Lernen auf die harte Tour
Das Framework-Verbot war die kontroverseste Entscheidung des Kurses. Studenten durften Bibliotheken für Embeddings (sentence-transformers), Vektor-Datenbanken (Qdrant, ChromaDB) und Web-Frameworks (FastAPI, Flask) verwenden. Aber kein LangChain, kein LlamaIndex, kein Haystack – kein RAG-Orchestrierungs-Framework.
Die Studenten nahmen das Verbot an. Der Grund war pädagogisch: Es geht um den Unterschied zwischen einem Tool benutzen und ein System verstehen.
Verstehen vs. Konfigurieren
LangChain macht RAG trivial. Du kannst eine Pipeline in 20 Zeilen Code bauen. Aber du verstehst die Kompromisse nicht. Bei bitaggregat brauchen wir Entwickler, die wissen, was unter der Motorhaube passiert.

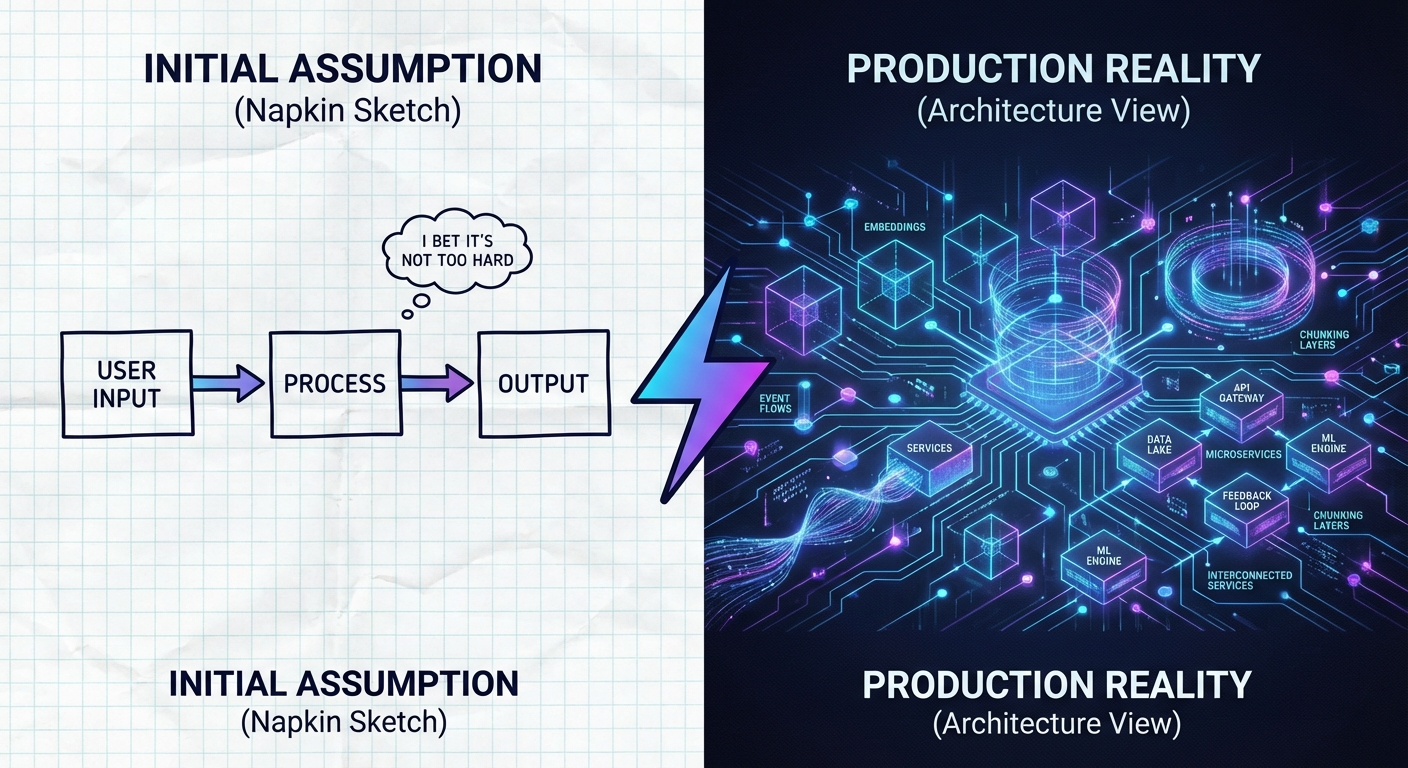
Der Comic illustriert, was passiert, wenn man ohne Verständnis drauflos baut: Was einfach erscheint („I bet it’s not too hard“), wird schnell komplex und ohne tiefes Verständnis verliert man die Kontrolle.
Was Studenten durch das Bauen von Grund auf lernten
Indem sie RAG selbst implementierten, entdeckten die Studenten Kompromisse durch Experimentation:
Chunking-Strategien: Teams testeten verschiedene Ansätze und merkten, dass nicht jede Strategie mit jedem Embedding-Modell funktioniert. all-MiniLM-L6-v2 hat nur 256 Token Kontextfenster, absatzbasiertes Chunking scheiterte damit bei längeren MARP-Abschnitten.
API-Keys und Git: Mindestens ein Team lernte auf die harte Tour, dass man keine API-Keys in GitHub-Repositories committen sollte.
LLM-Verhalten: Verschiedene Modelle folgen Anweisungen unterschiedlich genau. Die Studenten merkten, dass schlechtere Modelle einfach alles behaupten, was man ihnen im Kontext gibt, auch Retrieval-Ergebnisse mit miserablem Score. Bessere Modelle sind kritischer.
Prompt-Engineering: Kleine Änderungen am Prompt können große Auswirkungen haben. Und das Parsen unstrukturierter LLM-Ausgaben ist schwieriger als erwartet.
RAG ist keine Magie
Ein Ziel war das Entmystifizieren von RAG. Es ist eine Pipeline: Text extrahieren, in Chunks teilen, embedden, Vektoren speichern, ähnliche Vektoren abrufen, an ein LLM verfüttern. Jeder Schritt hat Kompromisse, aber keiner ist konzeptuell schwierig.
Die Studenten bewiesen das: Sie bauten funktionierende RAG-Systeme in 10 Wochen, mit begrenzter Erfahrung in verteilten Systemen. Das Framework-Verbot erzwang direkte Beschäftigung mit diesen Kompromissen. Zum Kursende verstanden sie, wie RAG funktioniert, nicht nur wie man es konfiguriert.
Du kannst ein System nicht sichern, das du nicht verstehst. Du kannst es auch nicht debuggen, erweitern oder erklären. Tools ändern sich, Frameworks entwickeln sich. Aber das Verständnis, wie man Text chunked, Events entwirft und Services strukturiert, überträgt sich auf jede Technologie.
Reflexionen
Der denkwürdigste Moment kam während der ersten Bewertung Anfang November. Ein Team stellte ihren MARP-Chatbot vor. Vorher hatten sie Erwartungsmanagement betrieben: Es gebe noch Bugs, sie seien nicht sicher, ob alles durchläuft. Dann stellten sie dem Chatbot eine Frage zu Prüfungsvorschriften und er antwortete korrekt, mit Zitaten, und gab sogar zu, als er für eine Folgefrage nicht genug Kontext hatte.
Die Studenten guckten sich ungläubig an. Dann fingen sie an zu lachen und haben es richtig gefeiert. Sie hatten nicht wirklich daran geglaubt, dass ihre Architektur unter Druck hält. Aber sie tat es.
Ich lernte, dass Studenten zu mehr fähig sind, als wir oft erwarten. Die Lernkurve war steil: RAG, Microservices, Events, Docker, Scrum, alles in 10 Wochen. Aber sie passten sich an. Sie hinterfragten, wie RAG-Frameworks funktionieren. Sie iterierten Anforderungen mit mir als Kunde. Sie bauten funktionierende Systeme von Grund auf.
Das war mein erster Durchlauf dieses Kurses. Einiges werde ich ändern.
Die Präsentationsskills waren insgesamt schwach. Bis auf eine Ausnahme sahen die Slides unprofessionell aus: Grafiken zu klein, unübersichtlich, kaum lesbar. Die Sprache zu umgangssprachlich für einen professionellen Kontext. Nächstes Mal werde ich das expliziter betonen: Behandelt jeden Sprint Review wie eine Client-Demo. Poliert eure Folien. Übt den Ablauf. Sprecht klar. Das ist genauso wichtig wie Code.
Beim Event-Schema-Design werde ich mehr Unterstützung bieten: mindestens ein oder zwei Beispiele gemeinsam live durcharbeiten, um zu sehen, was verstanden wurde und was nicht. Aber die Kernstruktur: RAG von Grund auf bauen, Microservices und Events verwenden, in Scrum-Teams mit echter Iteration arbeiten, das funktionierte.
Lehren als Nebenprojekt neben der Produktarbeit bei bitaggregat bereichert mich. Produktarbeit bedeutet viel mit Menschen reden, Politik, übersetzen von dem was nicht gesagt wird. Das ist grundsätzlich anders als Entwicklung und Technik. Im Kurs kann ich Skills aus beiden Disziplinen anwenden, und er hält mich mit den technischen Grundlagen verbunden, die das Tagesgeschäft manchmal überschattet.
Das MARP-Chatbot-Projekt war ambitioniert. Aber zu sehen, wie Studenten die Lücke zwischen Theorie und Praxis schlossen und etwas bauten, das funktionierte, das machte es wert.